Document Term Matrix Python Nltk
Well see how nlp tasks are carried out for. This is the fifth article in the series of articles on nlp for python.

Document Classification Using Python And Machine Learning

4 Text Vectorization And Transformation Pipelines Applied Text

Advanced Text Processing Using Nltk The Complete Guide

Document Term Matrix Youtube
One advantage of this is that the prior does not have to be conjugate although the example below uses the same beta prior for ease of comaprsion and so we are not restricted in our choice of an approproirate prior distribution.
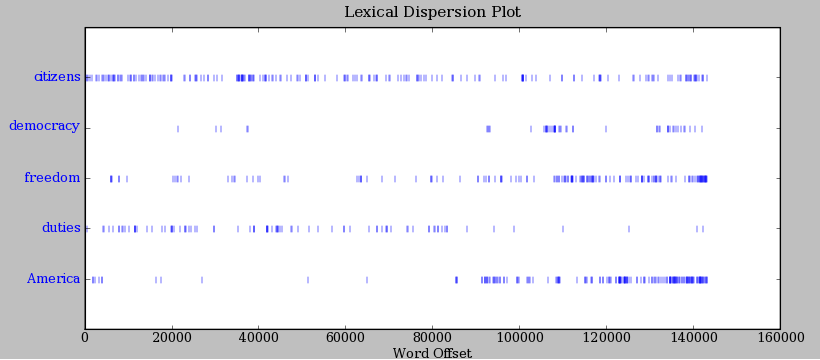
Document term matrix python nltk. When studying probability statistics one of the first and most important theorems students learn is the bayes theoremthis theorem is the foundation of deductive reasoning which focuses on determining the probability of an event occurring based on prior knowledge of conditions that might be related to the event. Read more to know how can document classification be performed using python machine learning. In this article well be learning about natural language processingnlp which can help computers analyze text easily ie detect spam emails autocorrect.
Understand why document classification is important. M1 is a document topics matrix and m2 is a topic terms matrix with dimensions n k and k m respectively where n is the number of documents k is the number of topics and m is the vocabulary size. In my previous article i explained how pythons spacy library can be used to perform parts of speech tagging and named entity recognitionin this article i will demonstrate how to do sentiment analysis using twitter data using the scikit learn library.
Keywords also play a crucial role in locating the article. Python nltk python macunix pip sudo pip install u nltk. Lda converts this document term matrix into two lower dimensional matrices m1 and m2.
In research news articles keywords form an important component since they provide a concise representation of the articles content.
Tutorial Text Analytics For Beginners Using Nltk Datacamp
Bag Of Words

Nlp Blog 5 Creating Document Term Matrix Dtm

5 Categorizing And Tagging Words
Sentiment Analysis

Document Similarity Tokenization And Word Vectors In Python With

Recommender System Based On Natural Language Processing
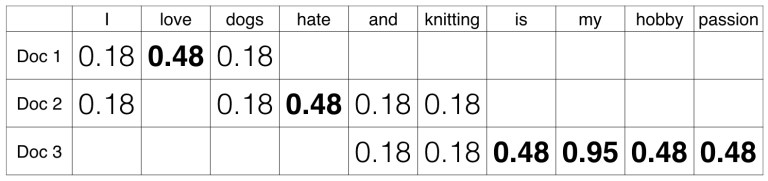
Tutorial Text Analytics For Beginners Using Nltk Datacamp

Introduction To The Nltk Library

4 Text Vectorization And Transformation Pipelines Applied Text

Ai With Python Nltk Package Oziras Com

Tutorial Text Analytics For Beginners Using Nltk Datacamp

10 Examples For Using Countvectorizer Kavita Ganesan
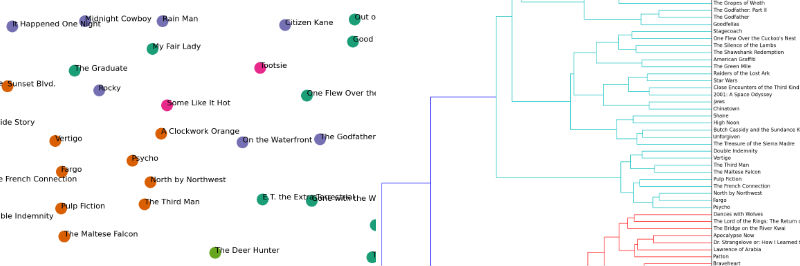
Document Clustering With Python

Lecture 4 Text Retrieval Models Ppt Download

A Smattering Of Natural Language Processing In Python
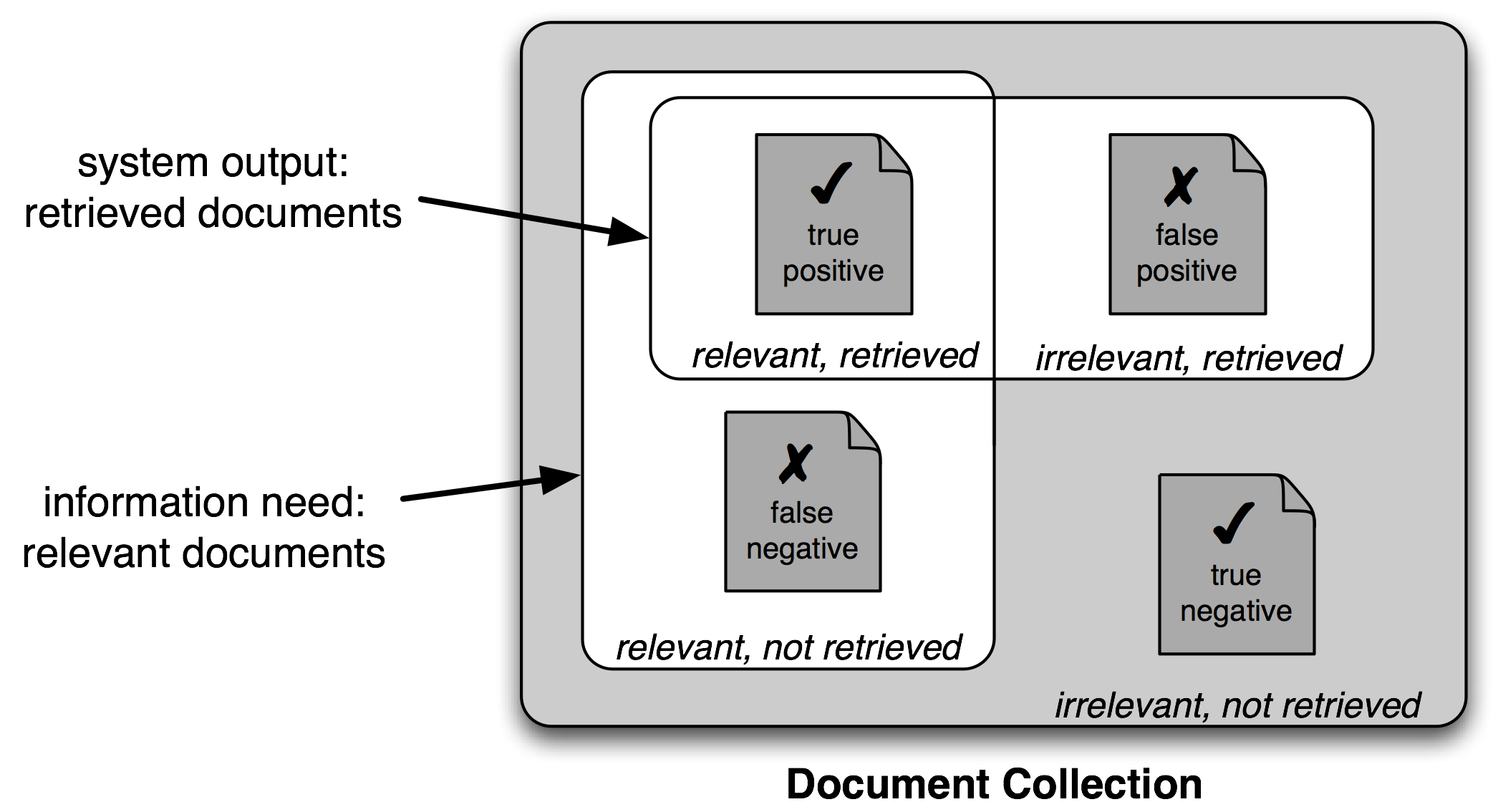
6 Learning To Classify Text
1 Language Processing And Python

Text Summarization In Python Things Grow
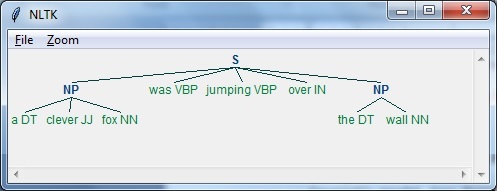
Ai With Python A Nltk Package Tutorialspoint
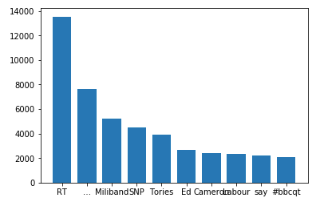
Natural Language Processing In Python 3 Using Nltk Becoming

Natural Languate Toolkit Nltk Tutorial In Python
Create Your Chatbot Using Python Nltk Predict Medium

Nltk Tumblr

Ultimate Guide To Deal With Text Data Using Python For Data
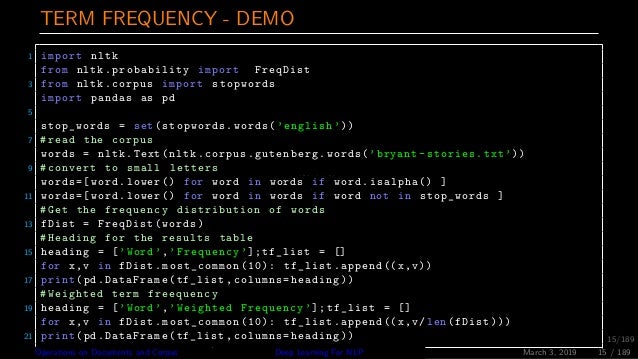
Nlp And Deep Learning
Writing Structured Programs

Natural Language Processing In Python 3 Using Nltk Becoming
Writing Structured Programs

Natural Language Processing With Python Nltk Cheat Sheet By

Natural Language Processing With Python Honing Data Science

Text Classification Using The Bag Of Words Approach With Nltk And

Text Classification With Python And Scikit Learn

Python Word Cloud And Nltk Shep Sheppard

Cosine Similarity Understanding The Math And How It Works With
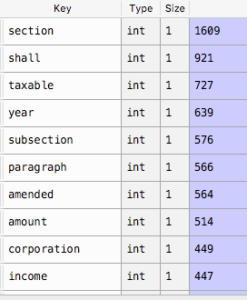
Python Word Cloud And Nltk Shep Sheppard
{kind=link}
Post a Comment for "Document Term Matrix Python Nltk"